Distributed code review on Selene — a real run, five lenses, one commit
A transcript-with-commentary of a real code review run on Selene. Five subagents, five lenses, one small delegation-lifecycle commit, dispatched as a single parallel batch. We walk through the fan-out, the findings clustered by theme, and the synthesis that turned them into concrete follow-ups.
On this page
Most of the code review you see in screenshots is theatre — a single model skims a diff, produces five bullet points, and stops. That is not what we want from a review, and it is not what our own team gets value from. A real review is a small crowd reading the same change through different eyes, each one bringing a bias we actually want, and then a synthesis step that reconciles them without flattening the disagreements.
This post is a transcript-with-commentary of one such review, run end-to-end on Selene. The subject is a real commit on our platform — 19cc424c, the fix that hardens how the agent lifecycle handles stuck pending calls and failed subagent reads. Five reviewers, five lenses, one commit, single parallel batch. The screenshots are from the actual session that produced this article.
The setup
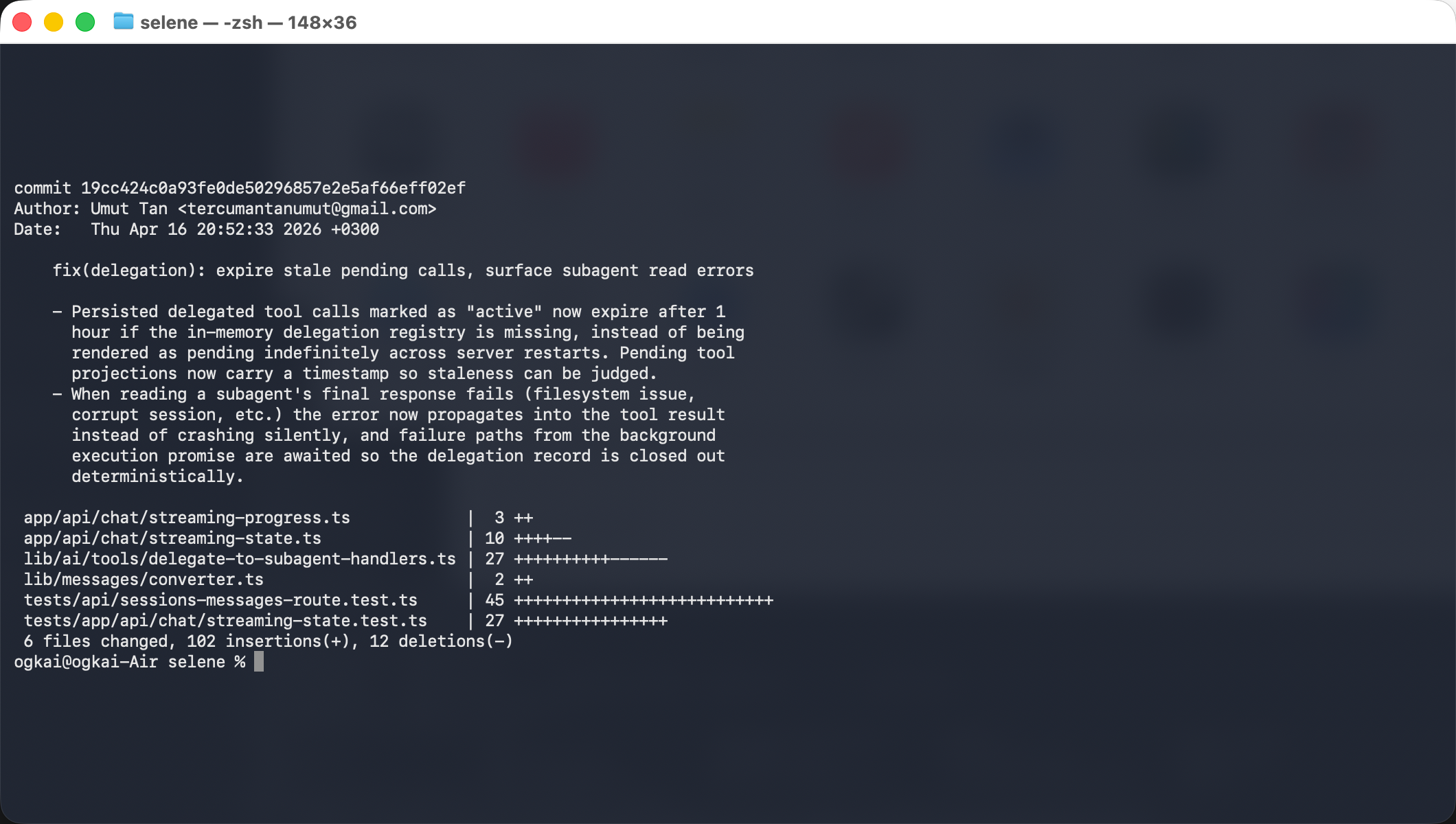
The commit is small enough to review deeply and complex enough to have real findings: six files, +102 / −12, touching the delegation handlers, the streaming state that projects pending tool calls to the UI, the DB message converter, and two new test files. Its stated goal is two-part:
Pending delegated tool calls should expire after one hour if the in-memory delegation registry is missing, instead of rendering as pending forever across server restarts.
When reading a subagent’s final response fails (filesystem error, corrupt session), the error should propagate into the tool result instead of being swallowed.
Both are the kind of small reliability change that is easy to approve at a glance and hard to get fully right. Perfect review bait.
The fan-out
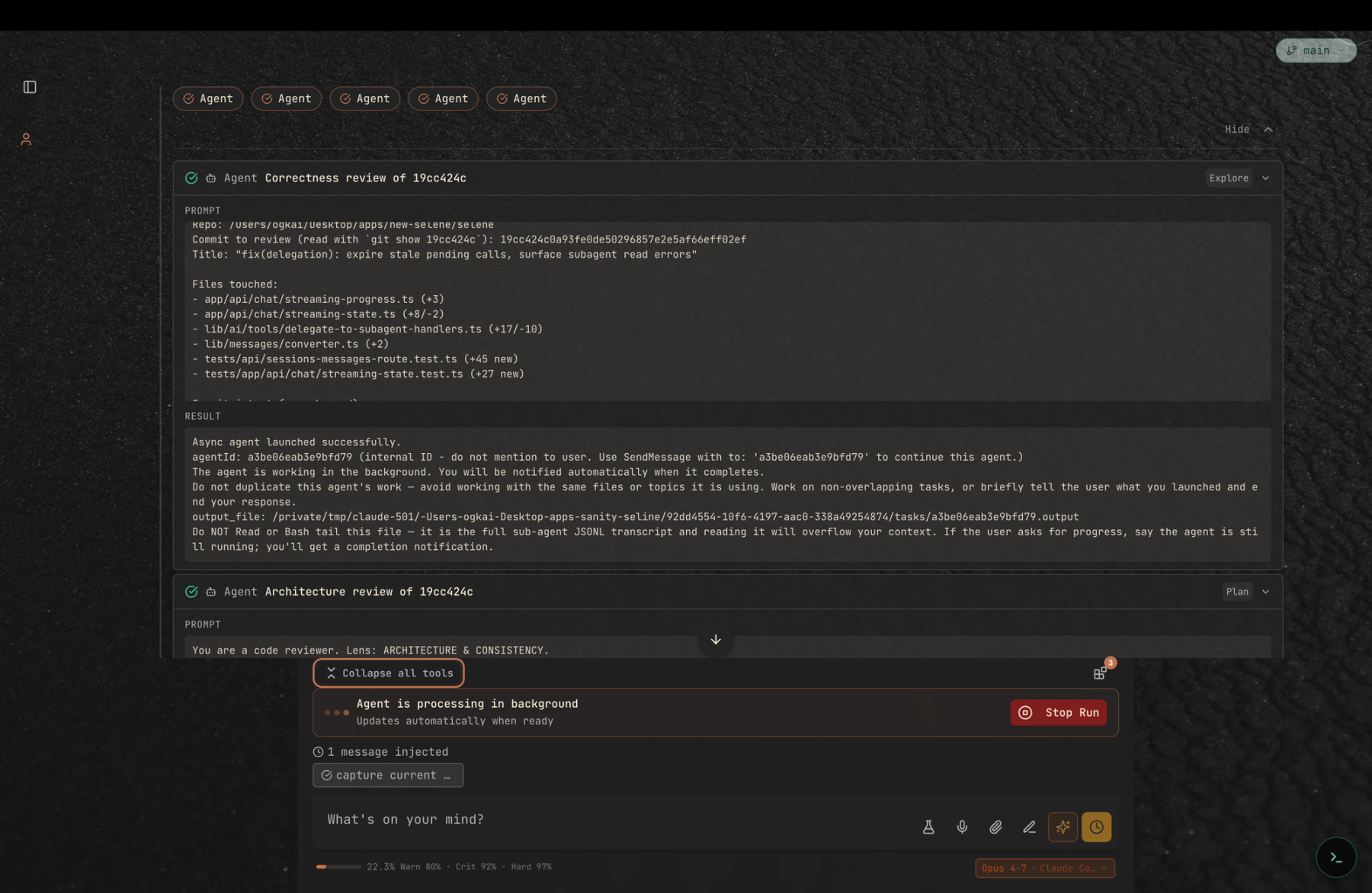
We picked five lenses — correctness, architecture, reliability, test coverage, and DX/docs — and dispatched a subagent per lens from a single turn. Each got a self-contained brief (the commit SHA, the file list, the lens, a hard word cap) and was told to cite file:line for every claim. They ran in parallel, in their own sessions, streaming results back asynchronously.
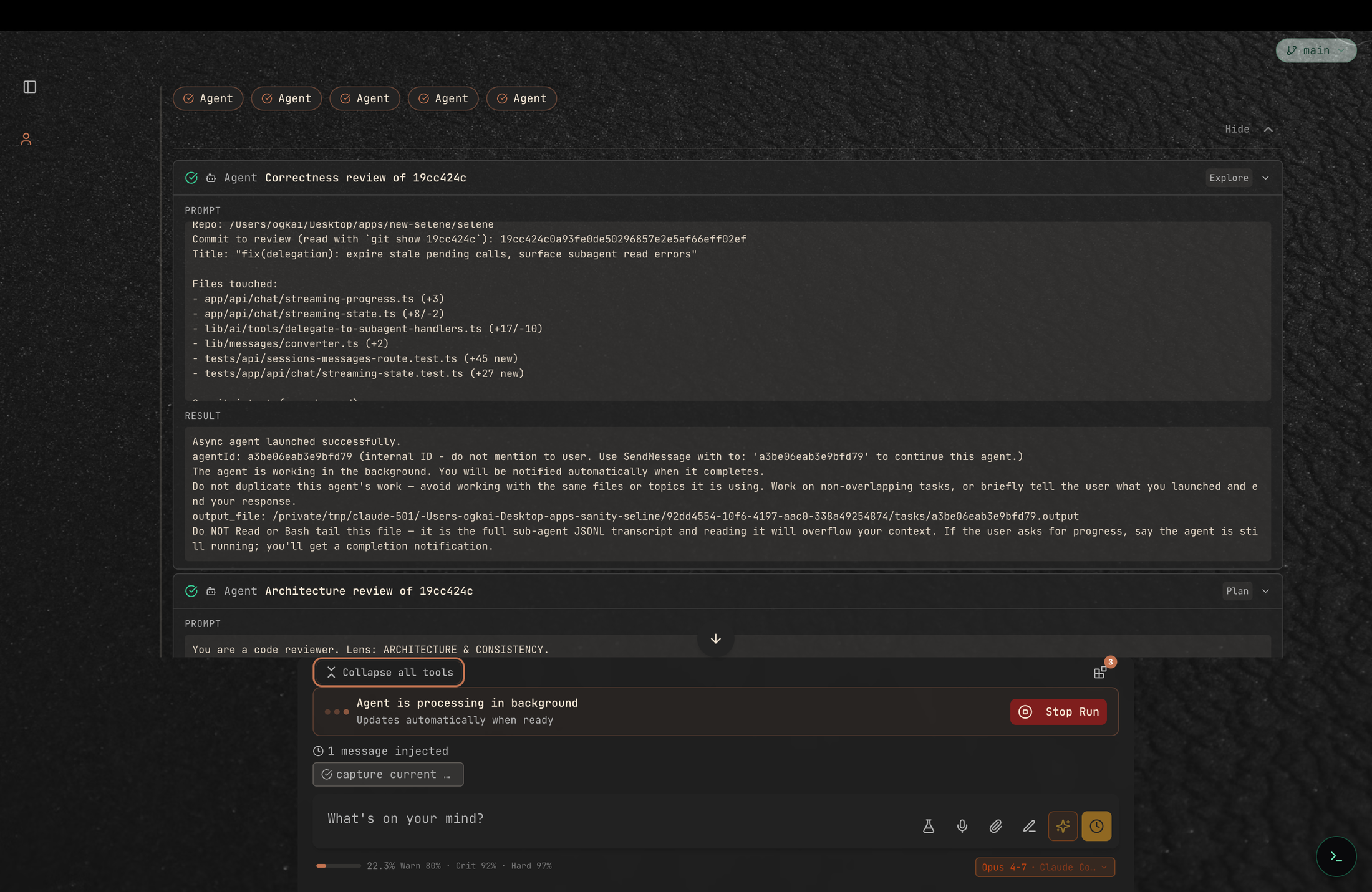
The fan-out itself is the first thing worth noticing. A lot of agent frameworks will happily advertise "multi-agent" and then serialise the calls under the hood — one subagent launches, finishes, then the next starts. That is not multi-agent, that is a for-loop. Selene dispatches the whole batch at once and lets each reviewer make its own tool calls independently while the top-level agent keeps the conversation responsive.
Results came back in a tight sixty-second window, one at a time. Nothing blocks while a reviewer is still thinking; you can scroll the earlier findings, open details on any tool call, or stop a reviewer that has gone off-track. Delegation feels like an editor with five tabs open, not a pipeline with five stages.
What the five lenses saw
The five reviewers agreed on the headline: the fix does what the commit message says, is a real improvement on the pre-change behaviour, and ships with its primary path tested. Where they disagreed is where the value came from. Clustered by theme:
Correctness — ship, with one defensive nit
The correctness reviewer walked both paths end-to-end. The expiry branch compares a projected timestamp against a one-hour TTL and correctly treats missing or unparseable timestamps as expired, so legacy pre-commit rows fail safely on first refresh. The error-propagation path now awaits notifyInitiatorSessionOfCompletion in both the success and the failure branches, so the delegation record closes out deterministically either way. One fragility nit: Date.parse is historically flexible with non-ISO inputs and can produce silently-wrong values on edge cases — a small hardening opportunity, not a blocker.
Architecture — correct fix, latent drift risk
The architecture lens was the most pointed. Two separate modules now carry one-hour TTL constants — DELEGATION_PENDING_TTL_MS in the streaming state and DELEGATION_STALE_TTL_MS in the delegation handlers — with identical values but no shared source. The next tuning pass will drift them, and one of the two paths will regress the original bug. Three projection sites independently stamp the same timestamp field, which means a future fourth site could silently skip the stamp and only the read-side tests would catch it. The underlying timestamp field on the DB type is also semantically ambiguous: a sibling type carries a field with the same name but a different meaning. The reviewer’s recommended follow-up was a small lifecycle module — one TTL, one helper, one source of truth — to collapse the duplication before a third consumer appears.
Reliability — single-process win, multi-worker question
The reliability reviewer enumerated failure modes. Server restart mid-delegation: covered. Legacy rows with no timestamp: covered and fail-closed (they seal rather than pending-forever). The open questions it flagged were the interesting ones. The in-memory registry is per-process; in a multi-worker deployment, worker B never sees worker A’s live delegations and the one-hour TTL quietly becomes the primary cross-worker source of truth. There is no dedupe between the stale-expiry path and a late-arriving completion from the subagent, so a tool call can be sealed as errored and then have a success notification fire later. And the newly-awaited notify function is not wrapped — if it throws, the unhandled rejection escapes in a place the previous fire-and-forget pattern did not reach. None of these invalidate the fix for the restart case it was designed for; they do define the envelope within which "ship it" is true.
Tests — strong on expiry, silent on error propagation
The test coverage reviewer built a coverage matrix. The expiry logic has a dedicated unit test for each branch — fresh projection, stale projection past the TTL, missing timestamp, and a repair-on-refresh integration test in the messages route. The one-hour boundary is pinned at t−61 minutes, so a regression tightening the TTL would fail fast. The gap is on the other half of the commit: the try/catch around extractFinalResponse — the entire mechanism that "surfaces subagent read errors" — has zero direct tests. The awaited background-promise failure paths are likewise untested. The reviewer suggested two specific test skeletons: one mocking extractFinalResponse to throw and asserting that the error string shows up in the final tool result, and one seeding a stale registry entry and asserting that the pending projection gets sealed. Both are small, both are high-signal.
DX & docs — the “M7” tag, and a missing lifecycle note
The DX lens is the one that does not produce blockers but produces the clearest "three-months-from-now" risks. The one-hour constant has a one-line "1h" comment but no explanation of what it is balancing; a newcomer tuning it will have to reverse-engineer the intent. A comment elsewhere in the code cites an "M7" tag that does not exist in the repo — likely a stale internal-milestone reference. The new timestamp field on the DB type has no JSDoc clarifying that it means "last projected-as-pending wall-clock time" rather than "when the call was issued," which is exactly the kind of ambiguity that becomes a bug the second a consumer rehydrates it. And nowhere in the repo is there a canonical "delegation lifecycle" document — no ADR, no CLAUDE.md section — that names the states (unsettled → settled → projected-stale → expired) and ties the write sites to the read side. Low-cost fixes, real long-term payoff.
The synthesis
A good synthesis has to do three things at once: preserve the reviewers’ disagreements, elevate the findings that have action items, and explicitly call out what was NOT raised. Here is the condensed verdict from this run, with severity preserved:
Ship — the commit fixes the bug it set out to fix, for the deployment shape the team targets today.
Follow up with a small delegation-lifecycle module that collapses the two TTL constants and the three projection stamp sites behind one helper.
Add the two proposed tests — one for subagent-read error propagation, one for TTL-based sealing — before the next release.
Track the multi-worker behaviour explicitly: either pin deployment to single-process, or add a cross-worker registry in a follow-up change.
Add a short "delegation lifecycle" section to the repo so the next engineer does not reverse-engineer the state machine from the code.
None of those are the kind of finding a single-pass skim of a diff produces. They came out of five independent passes with different priors, reconciled in one place.
Why run reviews this way
There is a quiet frustration that comes up regularly in developer communities — on r/AugmentCodeAI and others we read while researching content — about code review flows that feel brittle, expensive, or opaque. That feedback is partly what pushed us to build Selene’s delegation primitive the way it is: subagents with their own sessions, their own models, their own transcripts, and results that come back as inspectable messages instead of squashed text. The shape of the tool should encourage real review, not summary review. We are not saying this pattern is the only right one. We are saying this is what it looked like when we ran a single, small, commonplace review with it today.
If you want to try it, Selene is open source and self-hostable — bring your own provider keys, run everything locally if you want to, pick your own models per task. The same fan-out we used for this post works for architecture reviews, data migration diffs, or the kind of large refactor where no single reviewer could possibly hold the whole context.
The honest limits
One run is not evidence. We cherry-picked a small, well-scoped commit for this post; the same flow on a thousand-line refactor will surface different strengths and different failure modes. Reviewer outputs are also model-bound: the correctness lens leaned on a tool-heavy model that read the files; the DX lens benefited from a model with good naming intuition. You get to pick, per role — that is part of the design — but picking badly will make this flow no better than a single-pass review. And five is not a magic number. Some changes deserve three lenses; some deserve ten. The point is that the number should be a decision you make about the change, not a constraint the platform imposes.
Where to go next
The commit from this post is public on GitHub; the Selene repo is too. If you want to read the exact file:line citations the reviewers produced, they line up with the same paths listed in the git show at the top of this article — and if you are running Selene, the built-in Git Mode will walk the same diff without ever leaving the conversation. The next post in this series is a walkthrough of the tiny lifecycle refactor that came out of the architecture lens, and whether the follow-up review on that refactor finds anything the first round missed.
Thanks for reading. If you are building your own review flows and want to compare notes, the Selene GitHub discussions are a good place to do it.