My first SWE-bench Lite run with Selene cleared 60.67%
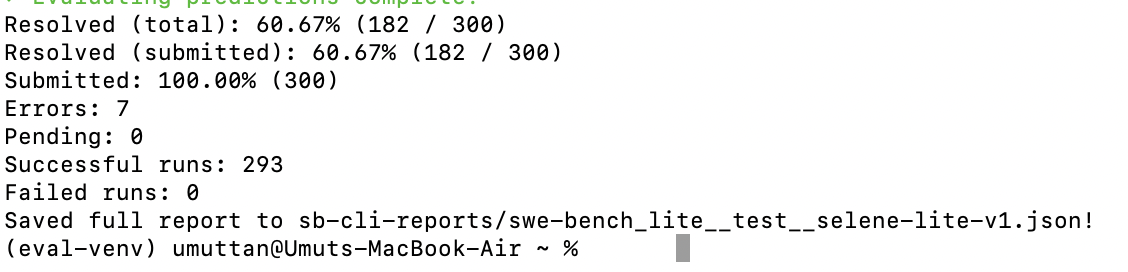
This was my first real SWE-bench Lite pass with Selene, not a polished rerun. I used Claude Opus 4.6 in non-thinking mode, kept the default Selene agent, ran tasks sequentially, and still landed at 182 resolved out of 300.
On this page
I wanted the first benchmark post here to be honest, not cleaned up after a bunch of retries. So this one is the real early pass: Claude Opus 4.6 in non-thinking mode, the default Selene agent, tasks processed one by one instead of in parallel, and a run that took about 18 hours to get through the full sweep.
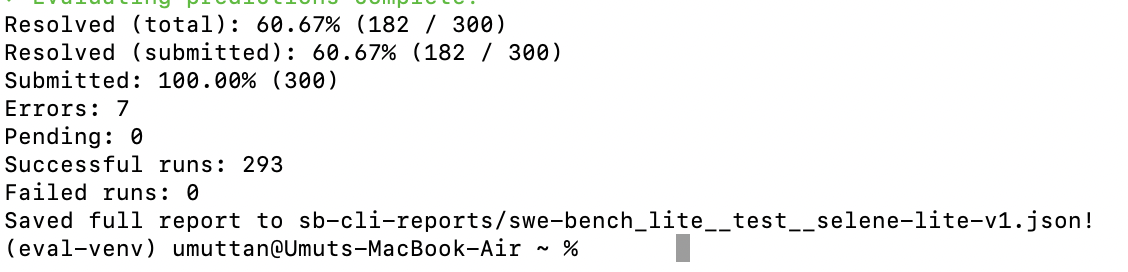
That run landed at 182 resolved instances out of 300 total, which is 60.67% on the full set. The report also showed 293 successful runs, zero failed runs, seven errors, and no pending tasks. For a first real pass on a pretty plain setup, that was enough for me to take seriously.
Why I care about this run
The part I care about is not just the number. It is that this run used the plain default Selene agent, not a benchmark-specialized coder prompt with heavily narrowed behavior. I wanted to see what the product could do in a harder environment before I started tuning anything around it.
That makes the result more useful to me. I do not read it as an optimized score. I read it as a baseline that already has real signal before I start squeezing the workflow, the prompt shape, or the model setup.
What the harness was actually doing
This was not a fake benchmark wrapper. The harness walked real SWE-bench instances, checked out the target repositories, handed the issue prompt through Selene, collected the patch output, and formatted predictions for evaluation. That matters because it means the run was exercising the actual agent stack rather than a toy shortcut.
In practice that meant auth, sessions, repository setup, file search, patch generation, retries, and evaluation formatting were all part of the path. That is much closer to product behavior than to a benchmark-only script.
What I would improve next
There is still obvious headroom here. The biggest thing is workflow shape: this run processed tasks sequentially, so it was basically a patient marathon instead of a faster distributed run. I also kept the default Selene agent and used Opus in non-thinking mode rather than pushing for a more aggressive coding setup.
So when I look at 60.67%, I do not read it as a ceiling. I read it as a useful first marker from a setup that was still intentionally pretty plain.
Why I am posting it anyway
I like posting this run early because it shows the kind of product I want Selene to become: not a benchmark-only machine, and not a hand-tuned lab curiosity, but a general agent system that can do product work and still show up with real numbers when pointed at something hard.
This one took a long time, used a default setup, and still crossed 60.67%. That feels like a good place to start from.