Augment Code vs Claude Code: the $3,000 vs $200 math, and the BYOK option most teams miss
A team swapped Augment Code at ~$3,000/month for Claude Code at $200/seat and saved 90%. The three AI coding pricing models — credit-metered, flat-rate and BYOK self-host — a five-developer month priced at provider list rates, and a migration checklist that works coming off any bundled tool.
On this page
Earlier this year a team lead posted a line that has since become a small meme in developer circles: roughly $3,000 a month on Augment Code across four seats, a swap to Claude Code at $200 a seat, and the same output with room to spare. That fifteen-to-one ratio has been doing a lot of work in AI-coding pricing conversations ever since.
The tweet is a good prompt, but it is not the full story. Augment Code and Claude Code are both well-built tools solving slightly different problems. The more useful question is not which is cheaper — it is what each pricing model is actually charging for, and which line items a team can take back into its own hands. That last part is where we come in.
The $3,000 vs $200 math, honestly
The team in question had four developers on a credit-metered plan and was watching the balance vanish in days, not weeks. The usage was real; the transcripts were long; the profile was heavy — the kind of heavy that per-action pricing is designed to discourage.
When they moved to flat-rate at roughly $200 per seat, total spend dropped from around $3,000 to around $800. Eight to ten times the perceived headroom at a fraction of the spend.
That is not a story about Augment being bad or Claude Code being good. It is a story about the mismatch between a credit model and a heavy usage profile. Credit pricing is reasonable for occasional users. Flat-rate is reasonable for steady power users. The $3,000 invoice was a signal that the team had crossed a threshold where the first model stopped serving them.
Three AI coding pricing models, three kinds of anxiety
Every AI coding tool is, under the hood, one of three things. Each produces a very different failure mode.
Credit / metered. You buy a balance; each action deducts from it. Honest about cost, but every keystroke becomes a budget question. The anxiety is friction.
Flat-rate subscription. Fixed monthly number, bounded by soft limits. Within them, you stop counting. The anxiety is the ceiling — and the fact that the provider sets it and can move it.
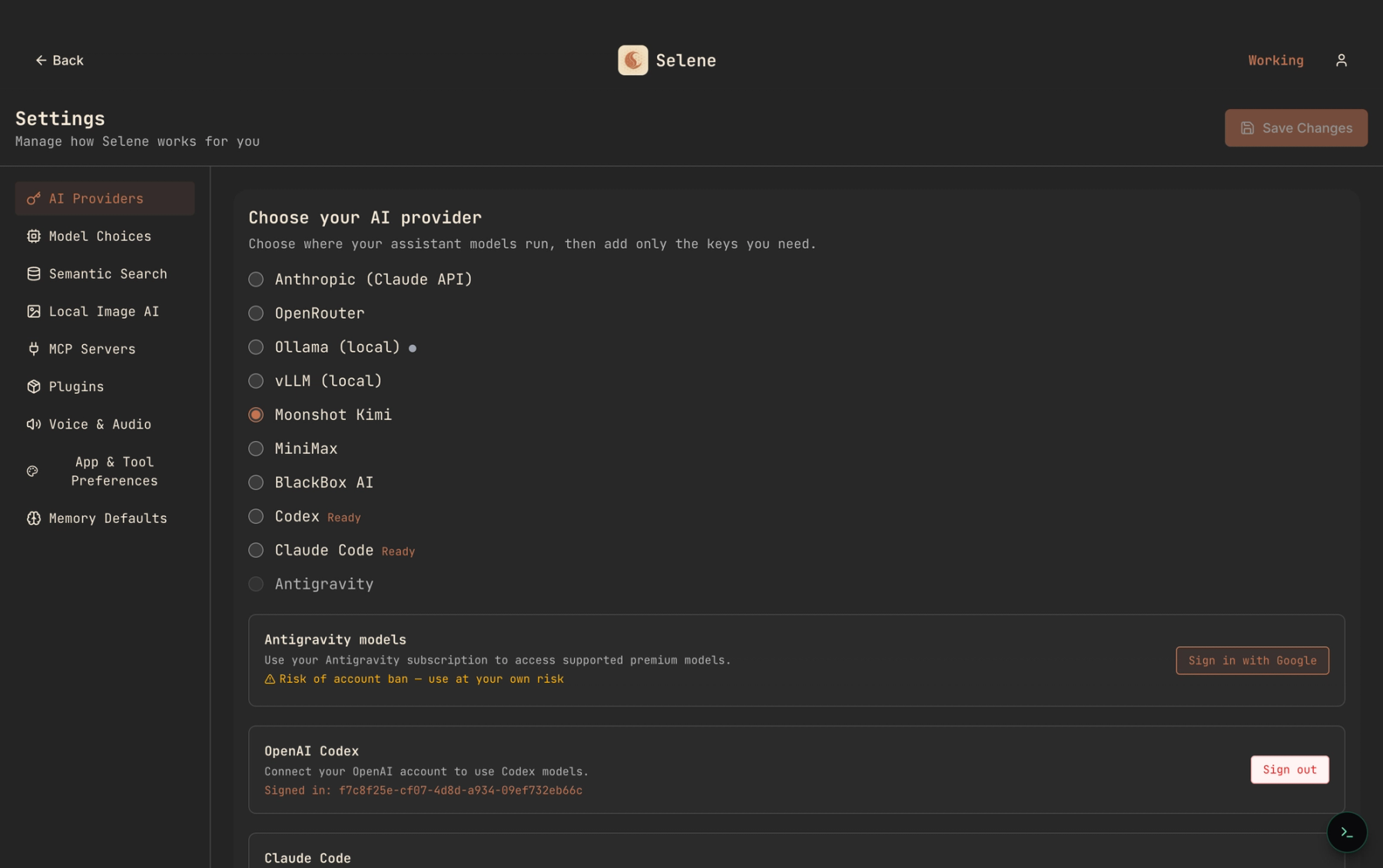
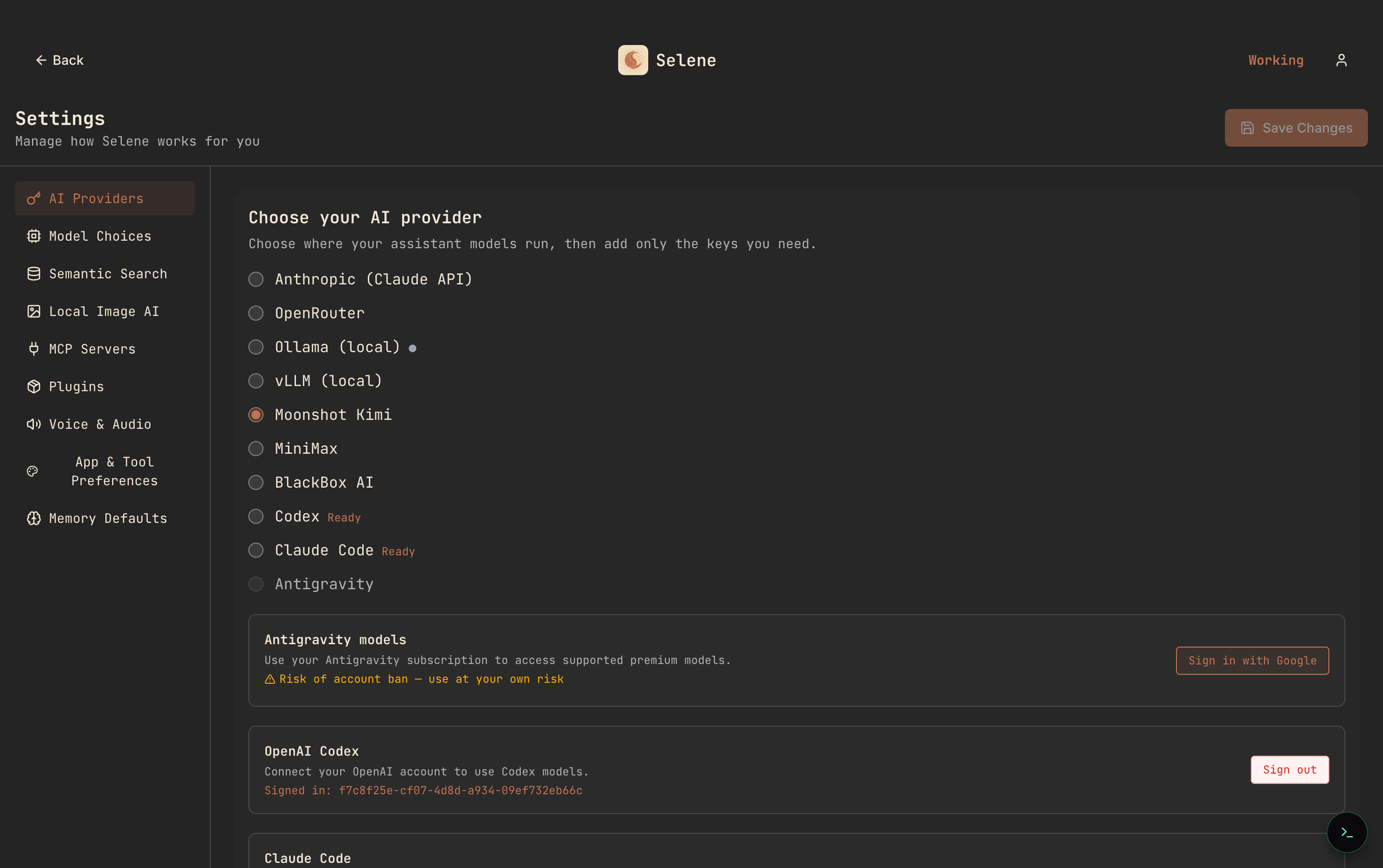
BYOK + self-host. Bring your own provider keys to an agent you run yourself. The bill is list-price API usage with no markup. The anxiety is introspection — and the upside is that a dial exists.
Each fits some teams and hurts others. What surprises people is that BYOK is often cheaper than flat-rate at real team scale — not by a little.
What codebase context actually costs
Most of the premium in team plans is paying for retrieval — the thing that makes an agent understand your repo instead of just your open file. This is real engineering, so charging for it is fair. The useful question is whether you want to pay as a monthly fee or as a one-time setup against your own storage.
A good small embedding model — BGE Small, 384 dimensions, ~130 MB — runs on CPU, embeds at review speed, and lives in a local vector store next to your repo. Every retrieval is a disk read. No per-query API, no "context engine went quiet this week" risk. A medium monorepo fits in under a gigabyte.
The trade-off is real: you give up the continuous-upgrade path a vendor can offer on its own embedding stack. For most working codebases, the accuracy ceiling of the good small models is high enough that the marginal recall is not worth the metered bill.
A five-developer BYOK month, priced at list
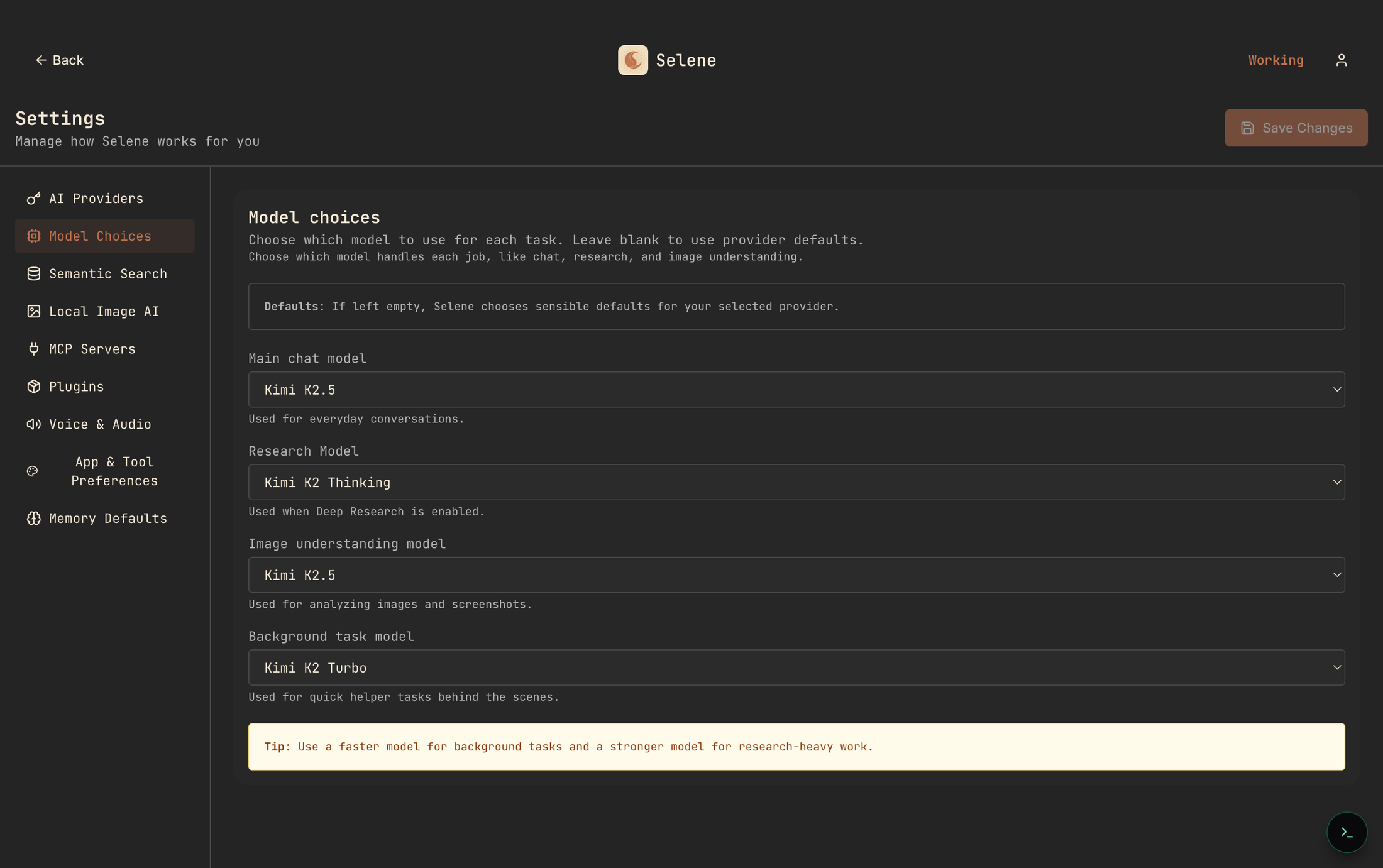
Here is the math we run internally when someone asks whether BYOK is worth it. Five developers, twenty working days, forty serious agent turns per developer per day — four thousand turns a month. We use a mix: stronger model for thinking-heavy turns, a cheaper fast model for helpers.
Stronger model, ~70% of turns at $3/M input, $15/M output, averaging 8k in / 1.5k out: 2,800 turns × ($0.024 + $0.0225) = ~$130.
Fast helper model, ~30% of turns at $1/M input, $5/M output, averaging 4k in / 500 out: 1,200 turns × ($0.004 + $0.0025) = ~$8.
Background helpers (summaries, titling, tool-routing): a rounding error, ~$5.
Total, at list price, for the whole team: roughly $140–$300 a month, depending on how spiky the usage is. Compare to flat-rate at $200 × 5 = $1,000, or the original credit-metered bill near $3,000. Any AI coding spend that touches four figures is, at current provider list prices, most likely covering a markup somewhere.
That markup is not evil — somebody has to pay for the engineering, retrieval, failover and polish. It is just useful to know it exists when you decide which layer of the stack to own.
The ownership dividend
Pricing is what teams notice first. Repricing is what bites latest. The year the credit conversion rate shifts, the year "fair use" limits tighten, the year a core feature moves behind a separate SKU — those are the moments you learn the bill is a policy, not a number. Policies change.
Open-source software cannot be silently repriced, because the license is a legal document and not a marketing page. If the upstream stops shipping updates tomorrow, your copy still runs. If it goes enterprise-only, your copy still runs. If it shuts down, your copy — still runs.
The same logic applies down the stack. Your embeddings live in a LanceDB directory on disk. Your chat history is a SQLite file. Your agent memory is a set of rows you can export. Your integrations are MCP servers you chose. When a vendor changes something, disagreement becomes a code-level choice, not a forum petition.
Migration checklist: from Augment Code or Claude Code to self-hosted BYOK
Teams that make the move follow roughly the same playbook. Nothing here is specific to one product — it works coming off any bundled AI coding tool.
1. Pull a real usage report. Read your last 60 days by action type. Count expensive "thinking" turns versus cheap helpers. That ratio decides which pricing model fits.
2. Pick a model mix, not a single model. Stronger model for main chat and research, a cheap-fast model for background helpers. You can change it next week.
3. Run the new setup next to the old one for a week. Real tasks on both. Compare not just outputs but the texture of the session — interruptions, error surfacing, how context holds over ten messages.
4. Port the codebase index. Point the new agent at the same folders. Let it embed overnight. Verify retrieval quality on the three or four queries your team actually runs.
5. Port the integrations. GitHub, issue tracker, database, browser automation — each is an MCP server you connect once and forget.
6. Cancel at the end of the billing cycle, not before. A week of double-paying is cheaper than a rushed migration.
Teams that skip a step almost always skip three or four — the parallel trial and the index port. They are, respectively, the most boring and the most important.
What we are not saying
We are not saying Augment Code is bad; it has a legitimately strong retrieval story and a lot of satisfied customers. We are not saying Claude Code is overpriced; for many individual developers it is the most humane way to buy AI coding. We are not saying every team should self-host — plenty are better served by someone else carrying the operational weight.
What we are saying is that when the $3,000 invoice lands, it is a useful prompt to actually run the numbers. Four thousand prompts a month, a model mix, a local index, a list of integrations. Summed at list price with no conversion layer in between, the spreadsheet tends to look like a budget a team can breathe in.
Where to go next
Selene is open source, self-hostable and BYOK. Install it, paste in your provider keys, sync a folder, run a real task. The provider picker at the top of this post is the first screen you touch; synced folders is the second; the per-task model picker is the third. Three screens, about ten minutes, and you will know whether the third option is the one your team wants.
If you are running the numbers for a team right now and the spreadsheet is not coming out the way the marketing pages suggested, we would like to hear about it. Selene’s GitHub discussions is the best place. Thanks for reading.